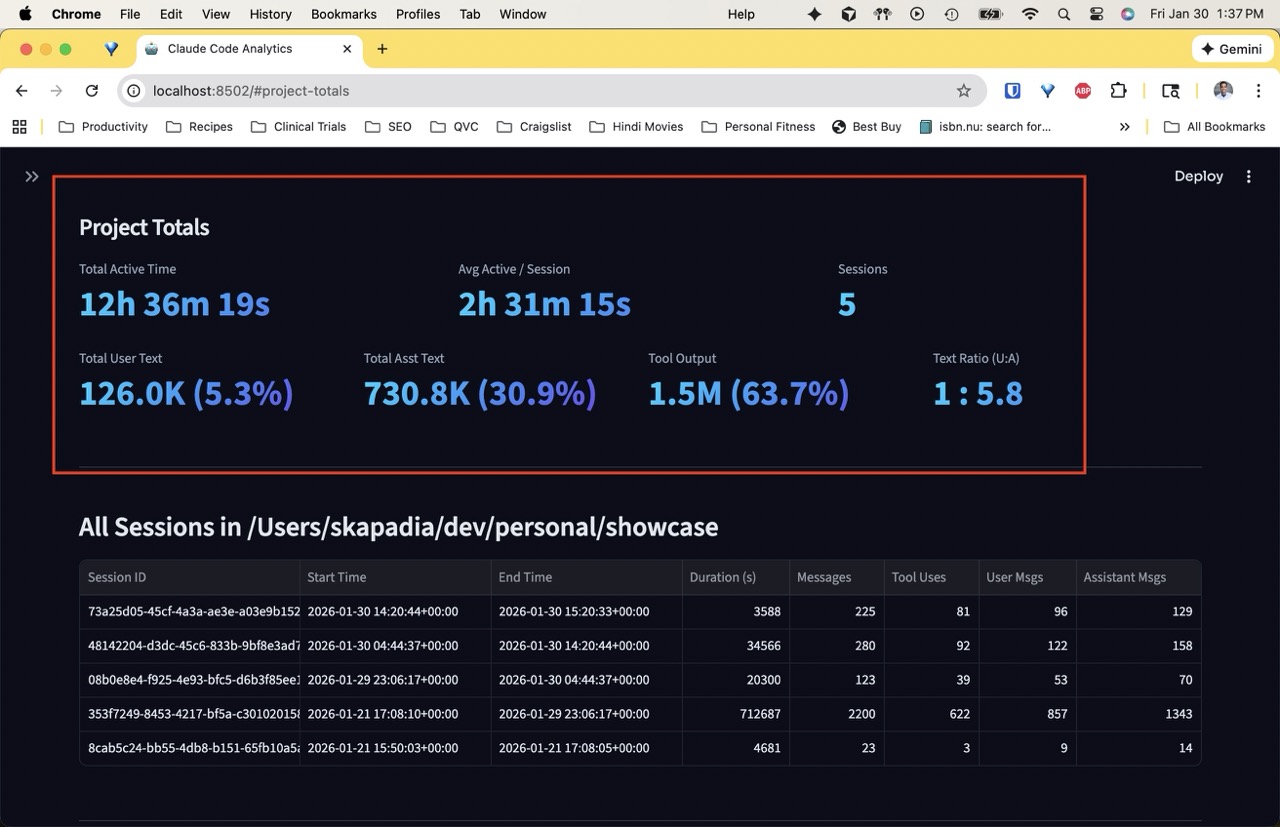
Added activity and volume tracking to the dashboard. The goal: understand not just what happened in a session, but how much effort went into it from each side.
Active time measures how long you were actually working, not just wall-clock duration. Gaps between messages longer than 5 minutes get capped -- so a session where you stepped away for lunch doesn't inflate your time. Shown at session, project, and aggregate levels along with an idle ratio.
Text volume breaks down all the text in a conversation into three categories:
- User text -- your prompts
- Assistant text -- agent prose + tool inputs (the commands it chose to run)
- Tool output -- system responses like file contents and command output
This distinction matters because tool output is neither party's work -- it's just the system echoing back results. Lumping it with assistant text made the assistant look like it was producing 5-10x the user's output, when really most of that was file contents being read back. Now the User:Assistant ratio only compares what each side actually authored, and tool output is shown separately.
The metrics appear in three places: per-session in the Browse Sessions page, per-project totals below that, and across all projects in the Analytics dashboard with a per-project breakdown table.